Wszystkie systemy kontroli wersji muszą rozwiązać ten sam podstawowy problem: w jaki sposób system umożliwia użytkownikom dzielenie się informacjami, a jednocześnie zapobiec przypadkowemu podstawianiu nogi jednym przez drugie? Zbyt łatwo o to, by jeden z użytkowników przypadkowo nadpisał zmiany innego w repozytorium.
Rozważmy następujący scenariusz: załóżmy, że mamy dwoje współpracowników, Jacka i Agatkę. Każde z nich decyduje się na edycję tych samych plików w repozytorium w tym samym czasie. Jeśli Jacek zapisze jako pierwszy swoje zmiany do repozytorium, jest możliwe że potem (kilka chwil później) Agatka może przypadkowo nadpisać je własną nową wersją pliku. Chociaż wersja pliku Jacka nie została utracona na zawsze (ponieważ system pamięta każdą zmianę), wszelkie wprowadzone zmiany jakie wykonał Jacek nie są obecne w nowej wersji pliku Agatki, ponieważ nigdy nie widziała zmian Jacka by od nich zacząć. Praca Jacka jest nadal faktycznie stracona - a przynajmniej nie ma jej w najnowszej wersji pliku - i to prawdopodobnie przez przypadek. Jest to na pewno sytuacja, której chcemy uniknąć!
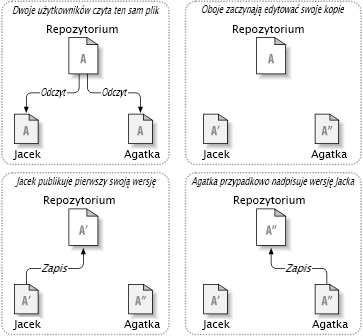
Wiele systemów kontroli wersji korzysta z modelu blokada-modyfikacja-odblokowanie by uporać się z problemem, co jest bardzo prostym rozwiązaniem. W takim systemie repozytorium pozwala tylko jednej osobie na raz zmieniać plik. Najpierw Jacek musi zablokować plik, zanim będzie mógł zacząć dokonywać zmian. Blokowanie pliku jest bardzo podobne do wypożyczenia książki z biblioteki, jeśli Jacek zablokował plik, Agatka nie może już dokonać żadnych zmian. Jeśli stara się ona zablokować plik, repozytorium odrzuci żądanie. Wszystko co może zrobić, to odczytać plik i czekać na Jacka, aż zakończy swoje zmiany i zwolni blokadę. Po odblokowaniu pliku przez Jacka, jego kolejka się kończy, a Agatka może z kolei zablokować i edytować.
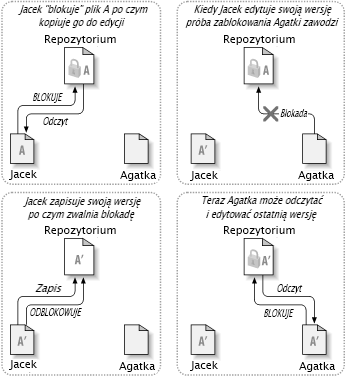
Problemem z modelem blokada-modyfikacja-odblokowanie jest to, że jest on trochę zbyt restrykcyjny, co często staje się przeszkodą dla użytkowników:
Blokowanie może powodować problemy administracyjne. Czasami Jacek może zablokować plik, a następnie o nim zapomnieć. Tymczasem Agatka, wciąż czeka by edytować plik i ma związane ręce. A potem Jacek idzie na urlop. Teraz Agatka musi znaleźć administratora by zwolnić blokadę Jacka. Sytuacja jest przyczyną długich niepotrzebnych opóźnień i straty czasu.
Blokowanie może to doprowadzić do zbędnej serializacji. Co zrobić, jeśli Jacek edytuje początek pliku tekstowego, a Agatka chce tylko edytować koniec tego samego pliku? Zmiany te wcale się nie pokrywają. Mogliby łatwo edytować plik jednocześnie, nie czyniąc wielkiej szkody zakładając, że zmiany były właściwie scalone. Nie ma potrzeby, by czekać na swoją kolej w tej sytuacji.
Blokowanie może stworzyć fałszywe poczucie bezpieczeństwa. Załóżmy, że Jacek blokuje i edytuje plik A, a jednocześnie Agatka blokuje i edytuje plik B. Załóżmy też, że A i B zależą od siebie nawzajem, a zmiany dokonane w każdym są semantycznie sprzeczne. Nagle A i B nie są już zgodne ze sobą. System blokowania nie był w stanie zapobiec temu problemowi - a jednak w jakiś sposób daje złudne poczucie bezpieczeństwa. Łatwo Jackowi i Agatce wyobrazić sobie, że blokując pliki, każde zaczyna bezpieczne, odizolowane zadanie, co hamuje omawianie ich niezgodnych zmian na wczesnym etapie.
Subversion, CVS i inne systemy kontroli wersji używają modelu kopia-modyfikacja-scalanie jako alternatywy blokowania. W tym modelu klient każdego użytkownika czyta repozytorium i tworzy osobistą kopię roboczą pliku lub projektu. Użytkownicy mogą następnie pracować równolegle, zmieniając swoje prywatne kopie. Na koniec prywatne kopie są scalone do nowej, finalnej wersji. System kontroli wersji często pomaga przy scaleniu, ale na koniec to człowiek jest odpowiedzialny by wszystko przebiegło poprawnie.
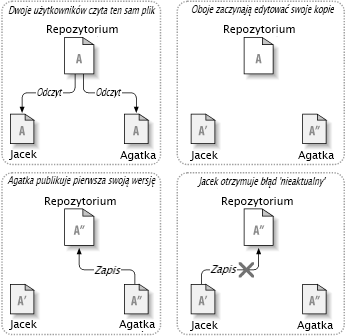
Oto przykład. Powiedzmy, że oboje Jacek i Agatka tworzą kopie robocze tego samego projektu, pobrane z repozytorium. Pracują jednocześnie, i wprowadzają zmiany w tym samym pliku A w swoich kopiach. Agatka zapisuje swoje zmiany do repozytorium pierwsza. Kiedy Jacek później próbuje zapisać swoje zmiany, repozytorium informuje go, że jego plik A jest nieaktualny. Innymi słowy, że plik w repozytorium został w jakiś sposób zmieniony odkąd ostatni Jacek skopiował go ostatnio. Tak więc Jacek prosi swojego klienta by scalić nowe zmiany z repozytorium do swojej kopii roboczej pliku A. Jest możliwe, że zmiany Agatki nie pokrywają się z jego własnymi i gdy już oba zestawy zmian zostaną zintegrowane, będzie mógł zapisać swoją kopię roboczą z powrotem do repozytorium.
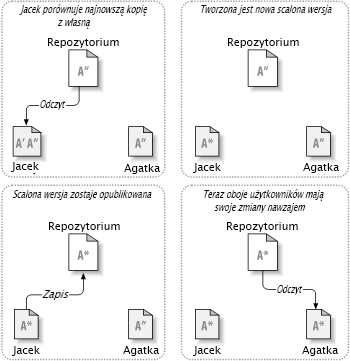
Ale co, jeśli zmiany Agatki pokrywają się ze zmianami Jacka? Co wtedy? Taka sytuacja nazywana jest konfliktem i zazwyczaj nie stanowi wielkiego problemu. Kiedy Jacek prosi swojego klienta o scalenie najnowszych zmian w swojej kopii roboczej repozytorium, jego kopia pliku A jest w jakiś sposób oznaczona jako pozostająca w stanie konfliktu: będzie on w stanie zobaczyć oba zestawy zmian powodujących konflikt i ręcznie wybrać między nimi . Należy pamiętać, że oprogramowanie nie może automatycznie rozwiązać konfliktu, tylko ludzie są zdolni do zrozumienia i dokonania niezbędnych inteligentnych wyborów. A gdy już Jacek ręcznie rozwiąże nakładające się zmiany (być może omawiając konflikt z Agatką!), może spokojnie zapisać scalony plik z powrotem do repozytorium.
Model kopia-modyfikacja-scalanie może wydawać się nieco chaotyczny, ale w praktyce działa on bardzo sprawnie. Użytkownicy mogą pracować równolegle, nie czekając na siebie. Gdy pracują na tych samych plikach, okazuje się, że większość ich jednocześnie wprowadzonych zmian nie pokrywa się wcale, a konflikty są rzadkie. Przy tym czas potrzebny do rozwiązywania konfliktów jest znacznie krótszy niż stracony przez system blokowania.
W końcu wszystko sprowadza się do jednego zasadniczego czynnika: komunikacja między użytkownikami. Gdy użytkownicy komunikują się słabo, narastają konflikty zarówno składniowe jak i semantyczne. Żaden system nie może zmusić użytkowników do doskonałego komunikowania się, i żaden system nie jest w stanie wykryć konfliktów semantycznych. Nie warto usypiać czujności fałszywą obietnicą, że system blokowania będzie jakoś zapobiegać konfliktom. W praktyce blokada wydaje się hamować wydajność bardziej niż cokolwiek innego.
Istnieje jedna znana sytuacja, w której model blokada-modyfikacja-odblokowanie wypada lepiej - to tam, gdzie występują pliki niemożliwe do scalenia. Na przykład, jeśli repozytorium zawiera kilka obrazów graficznych, i dwóch ludzi zmienia obraz w tym samym czasie, nie ma sposobu aby te zmiany mogły zostać połączone razem. Albo Jacek albo Agatka straci swoje zmiany.
Subversion używa domyślnie rozwiązania kopia-modyfikacja-scalanie, i w wielu przypadkach jest to wszystko co będzie ci kiedykolwiek potrzebne. Jednak od wersji 1.2 Subversion obsługuje również blokowanie plików, więc jeśli pracujesz z plikami niemożliwymi do scalenia lub jeśli po prostu kierownictwo zmusza was do stosowania polityki blokowania, Subversion nadal dostarczy potrzebnych funkcji.