Table des matières
Ce chapitre est une version légèrement modifiée du même chapitre dans le manuel de Subversion. Une version en ligne du manuel de Subversion est disponible ici : http://svnbook.red-bean.com/.
Ce chapitre est une brève et informelle introduction à Subversion. Si vous découvrez le contrôle de version, ce chapitre est certainement pour vous. Nous commencerons par une discussion sur les concepts généraux du contrôle de version, nous ferons notre chemin vers les idées spécifiques derrière Subversion et nous montrerons quelques exemples simples de Subversion en utilisation.
Bien que les exemples dans ce chapitre montrent des gens partageant des collections de code source de programmes, gardez à l'esprit que Subversion peut gérer n'importe quelle sorte de collection de fichiers - il ne sert pas qu'à aider des programmeurs.
Subversion est un système centralisé pour partager l'information. Son cœur est un dépôt, qui est un centre de stockage de données. Le dépôt stocke l'information sous forme d'une arborescence de système de fichiers - une hiérarchie typique de fichiers et de répertoires. Autant de clients qu'on veut se connectent au dépôt, puis lisent ou écrivent dans ces fichiers. En écrivant des données, un client rend l'information disponible pour les autres ; en lisant des données, le client reçoit l'information des autres.
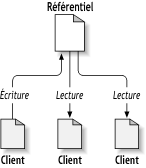
Alors pourquoi est-ce si intéressant ? Jusqu'ici, cela ressemble à la définition d'un serveur de fichiers typique. Et en effet, le dépôt est une sorte de serveur de fichiers, mais il n'est pas de votre genre habituel. Ce qui rend le dépôt de Subversion spécial est qu'il se rappelle de chaque changement jamais écrit : chaque changement de chaque fichier, et même les changements de l'arborescence des répertoires elle-même, comme l'ajout, la suppression et le réarrangement des fichiers et des répertoires.
Quand un client lit des données du dépôt, il voit normalement seulement la dernière version de l'arborescence des fichiers. Mais le client peut aussi voir les états précédents du système de fichiers. Par exemple, un client peut poser des questions historiques comme, « que contenait ce répertoire mercredi dernier ? », ou « qui sont les dernières personnes à avoir changé ce fichier et quels changements ont-elles fait ? » C'est ce genre de questions qui sont au cœur de n'importe quel système de contrôle de version : des systèmes qui sont conçus pour enregistrer et suivre les changements des données au cours du temps.