Índice
Este capítulo é uma versão ligeiramente modificada do mesmo capítulo no livro do Subversion. Uma versão em linha do livro do Subversion pode ser encontrada aqui: http://svnbook.red-bean.com/.
Este capítulo é uma introdução curta e casual ao Subversion. Se estás a iniciar-te no controlo de versões, este capítulo é mesmo para ti. Nós vamos começar com um discussão dos conceitos gerais de controlo de versões, abordar ideias específicas por detrás do Subversion, e mostrar alguns exemplos simples do uso do Subversion.
Mesmo que os exemplos deste capítulo mostrem pessoas a partilhar colecções de código fonte de programas, tem em mente que o Subversion pode gerir qualquer tipo de colecções de ficheiros - não está limitado a ajudar os programadores de computadores.
O Subversion é um sistema centralizado para partilha de informação. No seu cerne está o repository, que é um armazém central de dados. O repositório armazena informação na forma de uma firstterm>árvore de ficheiros
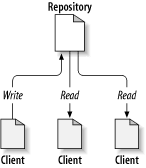
Então porque será isto interessante? Até agora isto parece-se com a definição de um servidor de ficheiros típico. E de facto, o repositório é uma espécie de servidor de ficheiros, mas não da sua raça normal. O que torna o repositório do Subversion especial é que ele lembra-se de qualquer alteração que lhe tenha sido alguma vez escrita: todas as alterações a qualquer ficheiro, e mesmo alterações na própria árvore de pastas, tal como adicionar, remover, e remodelar ficheiros e pastas.
When a client reads data from the repository, it normally sees only the latest version of the filesystem tree. But the client also has the ability to view previous states of the filesystem. For example, a client can ask historical questions like, “ what did this directory contain last Wednesday? ”, or “ who was the last person to change this file, and what changes did they make? ” These are the sorts of questions that are at the heart of any version control system: systems that are designed to record and track changes to data over time.